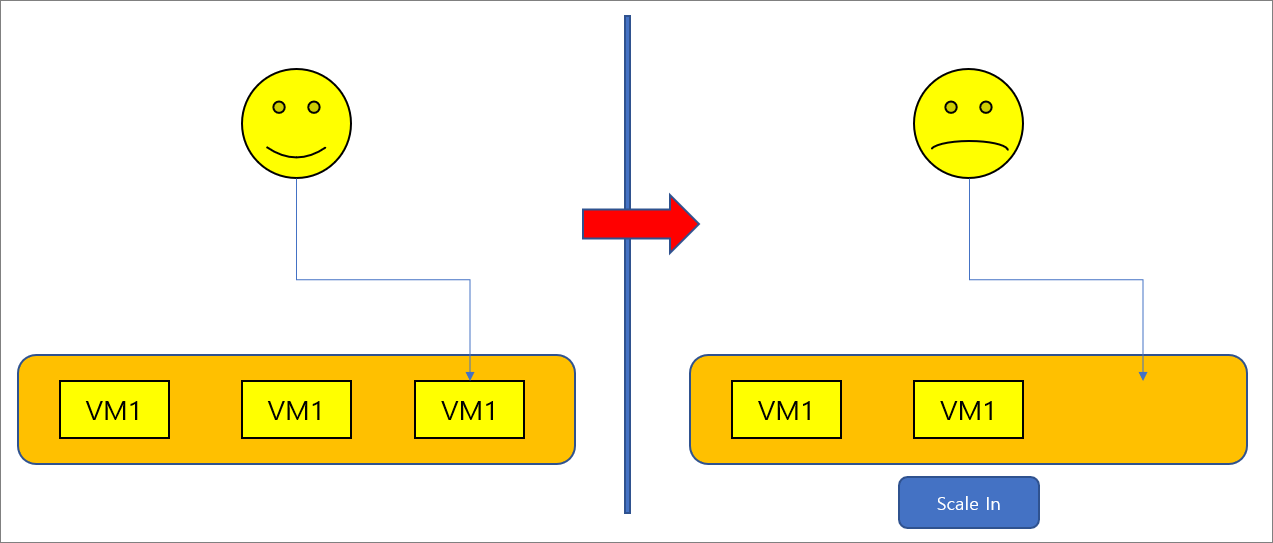
클라우드 VM의 Scale Out
클라우드 환경에서 Scale Out
다양한 클라우드 벤더에선 클라우드의 장점중 하나인 빠른 딜리버리를 사용하여 자동 확장 VM 서비스를 제공하고 있다. 그리고 구성 방법도 매우 심플하여 쉽게 사용할 수 있을 것 같지만 고려해야 할 사항이 몇 가지 존재한다.
1. 버전 관리
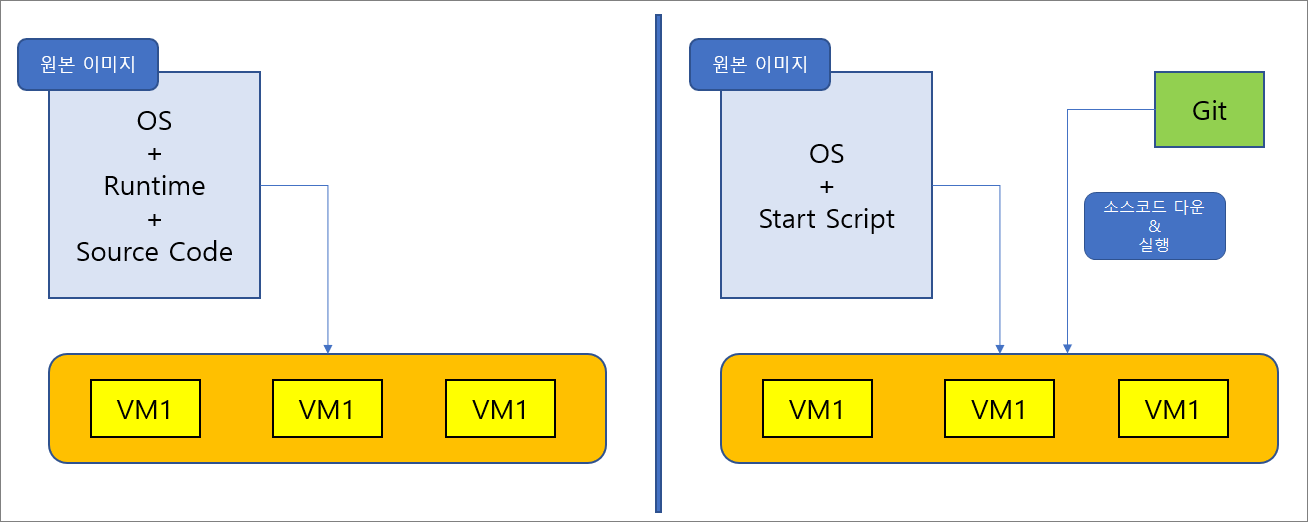
Scale Out VM은 빠른 배포를 목적으로 하기 때문에 미리 구성된 가상머신 이미지를 참조하여 수평 확장을 진행한다. 그렇기 때문에 이미 애플리케이션이 모두 탑재된 이미지를 만들어 두거나, OS가 설치되어있고 기본적인 보안 구성이 완료된 이미지로 VM을 만들도록 한 후, 시작 스크립트로 모든 애플리케이션을 작동시키도록 해야한다.
스노우 플레이크 서버 패턴
후자의 경우 이미 일반적인 서버 관리 방법으로 많이 쓰고 있다. OS 보안 패치가 필요할 경우 계속 패치를 해주고 애플리케이션의 경우 CI/CD 툴을 사용하여 배포하는 구조다. 이렇게 됐을 경우 문제점이 많아지게 된다. 우선 담당자가 바뀔 때 마다 이전에 설정했던 내용들에 대하여 모두 인수인계가 필요하며, 철저한 문서화가 필요하다. 이러한 사항들이 지켜지지 않으면 구성 내용을 파악하기 힘든 외계인 서버가 되어버리며 같은 설정이 다시 불가능하여 눈처럼 녹아내리는 형태의 [스노우 플레이크] 서버가 되어버린다.
피닉스 서버 패턴
스노우 플레이크 패턴의 문제점 때문에 나타난 서버 관리 패턴이 바로 피닉스 서버 패턴인데, 문제가 발생하거나 구성 내용이 업그레이드 되었을 경우 기존 서버에 덮어쓰기를 하는 것이 아니라 새로운 서버를 배포한다. 마치 불사조가 다시 태어나는 것 처럼 보인다 하여 피닉스 서버 패턴이라 불린다. 하지만 매번 서버를 만들고 이전 서버의 내용과 패치 내용을 적용하기엔 매우 시간이 많이 드므로, 서버의 이미지를 관리하게 된다. Kubernetes의 Deployment가 피닉스 서버 패턴을 사용한다고 볼 수 있다. 피닉스 서버 패턴의 이미지 종류는 3가지가 있다.
- OS Image : OS와 기본적인 보안 패치만 설정됨
- Foundation Image : OS Image + 미들웨어, 런타임, 웹서버 등이 설치됨
- Immutable Image : Foundation Image + 완전히 시동 가능한 애플리케이션이 설치됨
가상 머신 이미지를 만드는 작업은 사용자 손을 많이 타는 복잡한 작업이다. 손을 많이 탄다는 의미는 그만큼 실수할 확률이 높아진다는 뜻이다. 다행스럽게도 이런 과정을 자동화 해주는 오픈소스 소프트웨어가 있는데 바로 Packer다. Packer는 다양한 클라우드 벤더의 이미지를 만들 수 있는 기능을 제공하며 Azure에선 DevOps를 사용하여 후속 파이프 라인까지 만들어 이미지를 자동으로 업데이트 해줄 수도 있다. 배포 과정을 잠시 살펴보면 다음와 같다. (Azure 기준)
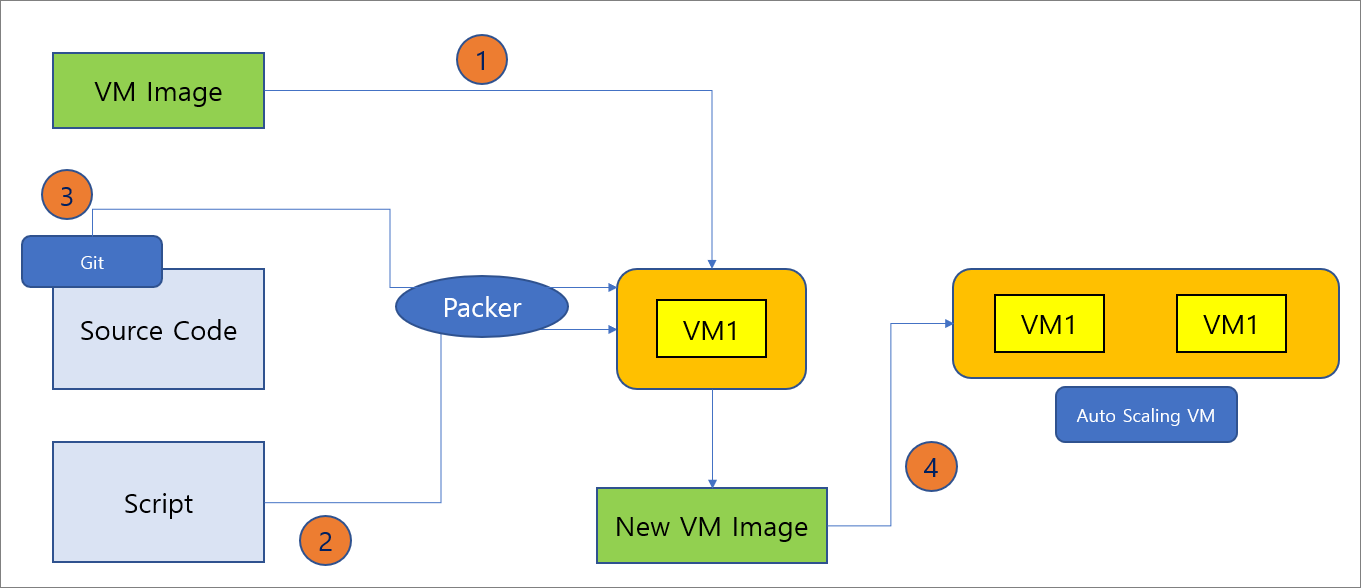
사용자 역할 : C
- P - 기존 이미지를 참조하여 가상 머신을 새로 배포한다.
- P - 사용자가 미리 지정한 스크립트를 참조하여 OS 내부에서 명령을 수행한다.
- P - 스크립트에 소스코드 다운로드가 있을 경우 Repository에서 소스코드를 다운 받는다. 그리고 부팅시 실행 가능한 상태(rc.local 등 사용 필요)로 만들어준다.
- C - Auto Scaling VM의 원본 이미지를 바꾸는 배포 파이프 라인을 만든다.
- C - 주어진 배포 전략에 맞게 노드를 업그레이드 한다.
** 2020년 7월쯤, 외식 프렌차이즈 서비스를 하는 고객이 Auto Scale Out 기능을 사용하고 싶다고 하여, Immutable Image를 만들고 Scale Out VM의 이미지를 교체하는 파이프 라인을 만들어야 한다고 안내를 해준 적이 있는데, 며칠 전 삼성전자에서 적용한 사례를 봤다. 내가 생각한 방법을 실제로 쓴 케이스는 처음 봤는데 참 신기한 경험이다.
버전 관리 결론
- 죽든 싫든 Scale Out 될 경우 원본 이미지를 항상 참조하기 때문에, Scale Out 가상머신은 패턴은 피닉스 서버 패턴을 사용한다.
- Foundation Image를 사용할 경우, 소스코드를 다운받고 애플리케이션이 실행될 때 까지 준비 시간이 오래 걸릴 수 있다.
- Immutable Image를 사용할 경우 완전히 실행 가능한 상태의 이미지를 빌드하는 파이프라인이 필요하다.
2. 배포 계획
새로운 버전의 애플리케이션을 출시했을 때 적절한 배포 계획을 세워야 한다. 새로운 버전의 애플리케이션이 항상 원하는대로 작동하면 좋겠지만, 그렇지 않은 경우가 많기 때문에 이전 버전으로 돌아갈 수 있는 롤백 계획도 같이 있어야 한다. 이를 위해 Blue-Green 전략을 사용할 수 있는데, 이 방식은 클라우드 벤더가 기능을 지원하는지 파악을 해야한다. Azure의 경우 노드의 업그레이드 라는 버튼을 클릭하여 원하는 노드만 새로운 이미지로 업그레이드 시킬 수 있다. 새 버전에 문제가 생겼을 경우 해당 버전이 배포된 노드에 원격으로 접속하여 애플리케이션을 중지하고, 원본 이미지를 이전 버전으로 되돌리고 새 버전이 배포된 노드를 다운그레이드 하는 작업이 필요하다. Azure의 경우 문제가 되는 VM을 삭제하면 자동으로 원본 이미지를 참조하여 노드를 다시 생성해준다.
3. 연결 드레이닝 처리
운영하는 웹 사이트의 부하가 줄어들었을 경우, 수평 확장된 수를 다시 줄이는 Scale In 작업이 진행된다. 이 경우 클라우드의 Scale Out 제품이나 클라우드 부하분산기는 백엔드에 아직 세션이 있는지 판단하지 않고 정해진 순서에 따라 VM을 삭제하게 된다. 그렇기 때문에 삭제된 VM에 사용자 세션이 남아있을 경우 해당 사용자는 현재까지 진행한 상황을 잃어버린다. 또한 트랜젝션이 도중에 끊겨버리는 좋지 않은 현상이 발생한다.